HTTP/2: Background, Performance Benefits and Implementations
On top of the infrastructure of the internet --- or the physical network layers --- sits the Internet Protocol, as part of the TCP/IP, or transport layer. It's the fabric underlying all or most of our internet communications.
A higher level protocol layer that we use on top of this is the application layer. On this level, various applications use different protocols to connect and transfer information. We have SMTP, POP3, and IMAP for sending and receiving emails, IRC and XMPP for chatting, SSH for remote sever access, and so on.
The best-known protocol among these, which has become synonymous with the use of the internet, is HTTP (hypertext transfer protocol). This is what we use to access websites every day. It was devised by Tim Berners-Lee at CERN as early as 1989. The specification for version 1.0 was released in 1996 (RFC 1945), and 1.1 in 1999.
The HTTP specification is maintained by the World Wide Web Consortium, and can be found at http://www.w3.org/standards/techs/HTTP.
The first generation of this protocol --- versions 1 and 1.1 --- dominated the web up until 2015, when HTTP/2 was released and the industry --- web servers and browser vendors --- started adopting it.
HTTP/1
HTTP is a stateless protocol, based on a request-response structure, which means that the client makes requests to the server, and these requests are atomic: any single request isn't aware of the previous requests. (This is why we use cookies --- to bridge the gap between multiple requests in one user session, for example, to be able to serve an authenticated version of the website to logged in users.)
Transfers are typically initiated by the client --- meaning the user's browser --- and the servers usually just respond to these requests.
We could say that the current state of HTTP is pretty "dumb", or better, low-level, with lots of "help" that needs to be given to the browsers and to the servers on how to communicate efficiently. Changes in this arena are not that simple to introduce, with so many existing websites whose functioning depends on backward compatibility with any introduced changes. Anything being done to improve the protocol has to be done in a seamless way that won't disrupt the internet.
In many ways, the current model has become a bottleneck with this strict request-response, atomic, synchronous model, and progress has mostly taken the form of hacks, spearheaded often by the industry leaders like Google, Facebook etc. The usual scenario, which is being improved on in various ways, is for the visitor to request a web page, and when their browser receives it from the server, it parses the html and finds other resources necessary to render the page, like CSS, images, and JavaScript. As it encounters these resource links, it stops loading everything else, and requests specified resources from the server. It doesn't move a millimeter until it receives this resource. Then it requests another, and so on.
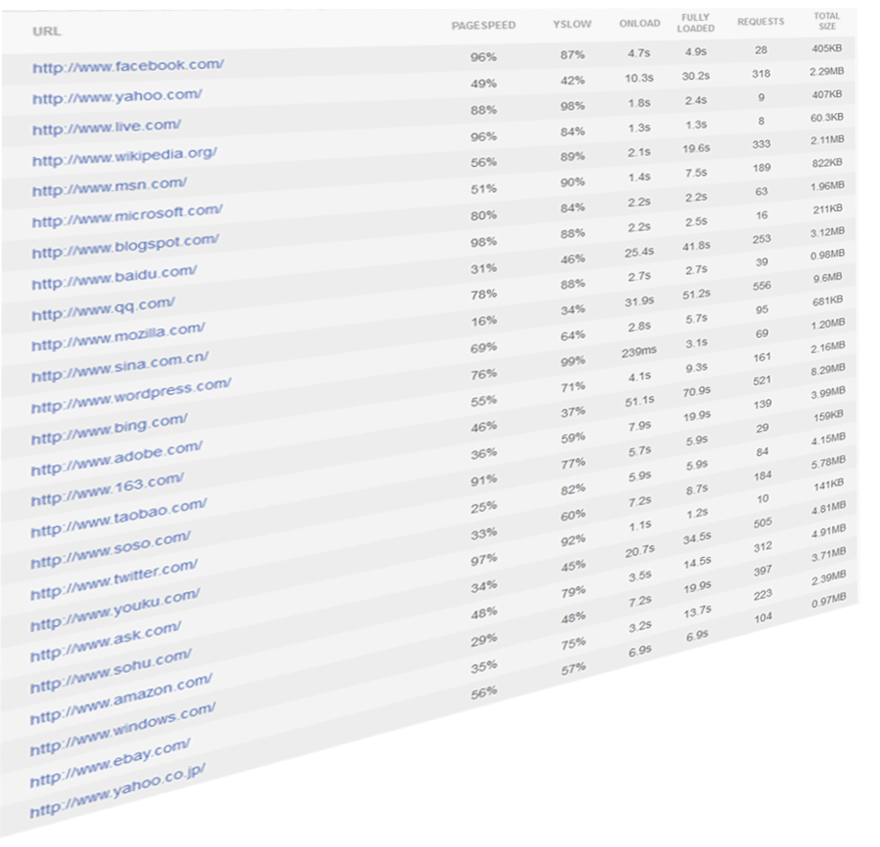
The number of requests needed to load world's biggest websites is often in couple of hundreds.
This includes a lot of waiting, and a lot of round trips during which our visitor sees only a white screen or a half-rendered website. These are wasted seconds. A lot of available bandwidth is just sitting there unused during these request cycles.
CDNs can alleviate a lot of these problems, but even they are nothing but hacks.
As Daniel Stenberg (one of the people working on HTTP/2 standardization) from Mozilla has pointed out, the first version of the protocol is having a hard time fully leveraging the capacity of the underlying transport layer, TCP.
Users who have been working on optimizing website loading speeds know this often requires some creativity, to put it mildly.
Over time, internet bandwidth speeds have drastically increased, but HTTP/1.1-era infrastructure didn't utilize this fully. It still struggled with issues like HTTP pipelining --- pushing more resources over the same TCP connection. Client-side support in browsers has been dragging the most, with Firefox and Chrome disabling it by default, or not supporting it at all, like IE, Firefox version 54+, etc.
This means that even small resources require opening a new TCP connection, with all the bloat that goes with it --- TCP handshakes, DNS lookups, latency… And due to
Truncated by Planet PHP, read more at the original (another 3898 bytes)